Project 2 - Predicting Oscar Nominations
In project 1, we focused on learning the fundamental components of the Data Science “toolkit” by analyzing NYC MTA Subway data. In project 2, code-named Project Luther, we built on those fundamentals and learned new concepts and analysis techniques such as web data scraping and linear regression to predict something about the movie industry. I decided to focus on trying to predict the number of Oscar nominations for a movie.

Data wrangling
I spent a majority of my time getting my hands dirty collecting, exploring, cleaning, and transforming the movie data. I obtained the data by scraping Box Office Mojo and joining that with data I collected from the Open Movie Database (OMDB) API. The image below shows the evolution of the data from the raw movie data to the data I used to run the linear regression model.
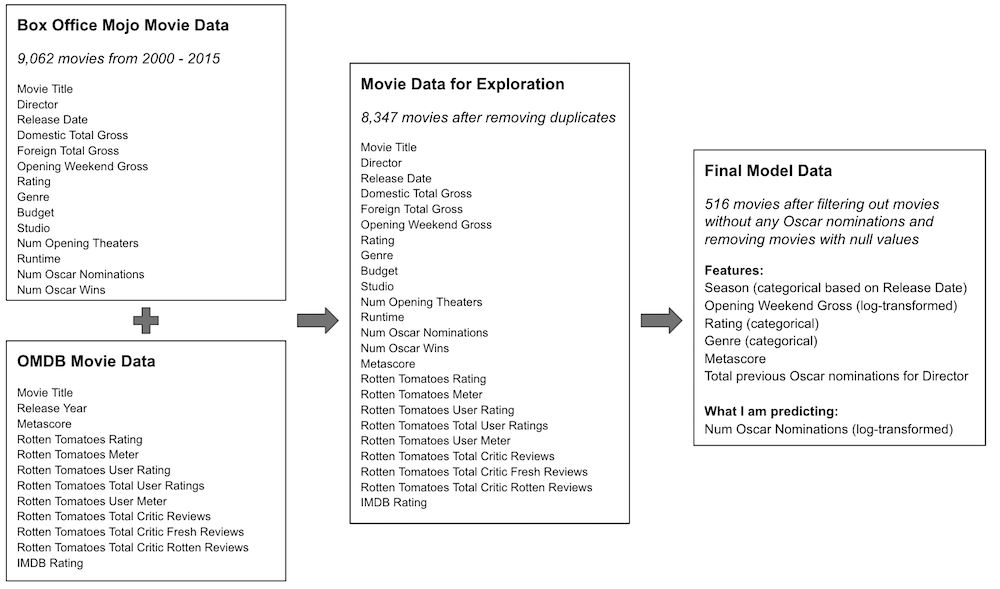
The final dataset I ended up using for my model only contained 516 movies of the original 9,000+ movies I collected from Box Office Mojo. This was because I tried to simplify the analysis by focusing only on movies that had at least one nomination and filtering movies with null values.
The model

No! Not that kind of model! I’m talking about the final linear regression model I used to predict the number of Oscar nominations for a movie.
After iterating over many different models, I settled on the following model for my final analysis:
- What we’re trying to predict (i.e., dependent variable): # Oscar Nominations
- Features we’re using to predict (i.e., independent variables):
- Opening Weekend Gross (log-transformed)
- Metacritic Score
- Total previous nominations for Director
- Season (categorical based on Release Date)
- Rating (categorical)
- Genre (categorical)
This Oscar nomination prediction business isn’t as easy as it sounds
The final linear regression model I developed was not a robust basis for prediction given the R-squared value of 0.426. However, there are a few conclusions we can draw from the model results:
- Season: Fall/Winter have positive effect
- Genre: Drama has highest positive effect on nominations of all genres (Animation has negative influence)
- Previous director nominations, Metascore and Opening Weekend Gross positively influence nominations
Key takeaways
Here are my major takeaways from project 2.
The importance of speed when working with large data sets

Overall, being able to collect data quicker allowed me to experiment with more data sets and models. Here are some techniques I used to help speed up my analysis.
- Using event pooling to speed up scraping - Check out my previous article where I described the different methods I used to speed up data scraping and the summary of associated performance improvements.
- Pickling to make future start-up time faster Check out this post by my classmate, Ian London on how to use Pickling in Python to save data that required a time-consuming process to collect (scraping the movie data in my case).
- Code in small chunks - functions on large datasets can be very time-intensive. To save time in coding these functions, I like to perfect the functions on small, more manageable subsets of the overall dataset. For example, to develop the function to scrape data from Box Office Mojo, I first developed the code to collect data for a single movie before scaling the function up to collect data from an entire year, and then scaling it up again to scrape movie data for multiple years.
Pre-processing techniques for linear regression models
Here are some of the techniques I used to satisfy the linear regression model assumptions:
- Correlation analysis to identify collinearity issues
- Plotting data distributions to understand what transformations may be necessary
Deduplication to clean dirty data
In exploring my data, I realized that there were certain movies that were duplicated in my dataset. To remove the duplicates, I found the pandas.DataFrame.duplicated function to be very helpful.
Feature engineering based on prior data
Engineering data for a movie director’s total previous Oscar nominations was not an easy task. I couldn’t simply create a new table that had director and a sum of all their Oscar Nominations, and then join that table back to the main movie data set. The problem is that the number of previous Oscar nominations by a director changes over time. As an example, Ridley Scott directed major movies that received Oscar nominations such as Gladiator in 2001, American Gangster in 2007, and The Martian in 2015. However, the total number of previous Oscar nominations for Ridley Scott movies was different for each movie since the total is a running cumulative sum of the movies released beforehand.
To address the issue, I used Pandas to first do a self-join using a merge() and then groupby() with a sum(). Here’s the exact code I used:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
def addPrevDirectorNoms(df):
'''
Add total previous oscar nominations for the director's movies that occurred before a
movie was released
'''
# create a new dataframe with only the director, noms (nominations), and release_date
# also drop any movies without any noms
director_prev_noms_df = df[['director','noms', 'release_date']].dropna(subset=['noms'])
# convert noms to an int
director_prev_noms_df['noms'] = director_prev_noms_df['noms'].astype('int')
# self-join on director
director_prev_noms_df = pd.merge(director_prev_noms_df,\
director_prev_noms_df, on='director')
# remove any nominations that happened after a particular momvie was released
director_prev_noms_df = director_prev_noms_df[director_prev_noms_df['release_date_x']\
> director_prev_noms_df['release_date_y']]
# get a sum of all the previous nominations for the director's movies
director_prev_noms_df = director_prev_noms_df.groupby(['director', 'noms_x',\
'release_date_x'], as_index=False).sum()
# merge the previous nomination data back to the original dataframe
prev_noms = df.merge(director_prev_noms_df, left_on=['director', 'release_date']\
, right_on=['director', 'release_date_x'], how='left')
# when a movie director has never had a movie that had any previous nominations,
# set their previous nominations to 0
prev_noms['prev_noms'] = prev_noms['noms_y'].fillna(0).astype(int)
# drop some of the duplicated columns that were created as part of the merges
prev_noms = prev_noms.drop(['noms_y','noms_x'], 1)
# return the new dataframe that has the previous nominations added as a column
return prev_noms
Additional familiarity with the Data Science “toolkit”
- Data analysis and SQL-like data manipulation in Python using Pandas
- Web scraping using Beautiful Soup
- Using Linear Regression techniques to predict a numeric value
- Cross-validation with sklearn
Future work
Here are some quick thoughts on how I may be able to improve the model in the future:
- Experiment with models other than linear regression (e.g., reformulate the problem as a classification problem and use different classification algorithms on the data)
- Focus analysis on a subset of Oscar nomination categories to avoid differences in categories (e.g., Best Picture vs. Best Score)
- Add additional historical Oscar nominations/wins for full cast (not just director)
- Research techniques from other Oscar prediction analyses
Project source
Interested in the nuts and bolts of the project? Check out the project source code on my github.