Faster Python Data Scraping with gevent.pool
In my second project at Metis, I wanted to develop a linear regression model to predict the number of Academy Award nominations for a movie. In order to collect the data to develop my model, I had to scrape a lot of movie data from BoxOfficeMojo.com. One of the major issues with collecting the data was how slow it was to scrape the data and transform it to a format that I could use to develop the model. After doing some high-level performance profiling of my code using cProfile, I discovered the major bottleneck was the http request for each movie (using the python requests package).
To quantify how slow it was, using my initial code (the “Base” case in the analysis below), it took ~0.1 seconds per movie for each http request. That might not sound like much, but to collect the data for the 9000+ movies from 2000-2015 on BoxOfficeMojo.com, it would take 15+ minutes! That’s a long time, especially as we’re constantly iterating on the data we’re collecting as we develop the model.
Therefore, I set out to devleop a way to improve the performance so I could scrape movie data quicker. In the remainder of this post, I’ll take you through a comparison of the performance of the different methods I tried, as well as the fastest method I settled on using. Here are the different methods I’ll be comparing:
- Base Case making
Nrepeated HTTP requests withrequests - HTTP Sessions (
requests.Session()) makingNrepeated HTTP requests with the same HTTPSession - Pooling HTTP Requests (
gevent.pool) using pooling to makeNrepeated HTTP requests **my final solution - Sessions and Pooling (
requests.Session()andgevent.pool) combining methods (2) and (3)
Note: to make this code and analysis easier to follow, I’ll be making all http requests to the same url and won’t be performing any of the transformations that I had to do to the movie data.
Getting Started
First, we’ll import all the python packages we need.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# import requests so we can make http requests
import requests
# We'll use gevent for pooling requests.get() calls
import gevent.monkey
gevent.monkey.patch_socket()
from gevent.pool import Pool
# We'll use matplotlib and seaborn to plot function performance
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set_style('whitegrid')
# ...and a few other common packages that we'll use
import time
import numpy as np
from pandas import DataFrame
To keep things simple, we’ll make all our http requests to http://www.boxofficemojo.com. Hopefully they don’t mind us making so many requests to their servers!
1
url = 'http://www.boxofficemojo.com/'
Let’s also create an empty list, performance_results, to track the performance of each function
1
performance_results = []
Next, we’ll create the simulateHttpRequests function that will allow us to simulate repeated calls (defined by N, aka the number of http requests) to our different http request functions we’ll be creating and return the performance results for each call.
1
2
3
4
5
6
7
8
9
10
def simulateHttpRequests(my_func, url, method_name):
'''
Simulates making http requests using different functions and returns
a dictionary with information about the function and it's performance
'''
times = []
for N in np.arange(200, 1001, 200):
secs = my_func(url, N)[1]
times.append({'method': method_name,'N': N, 'seconds': secs})
return times
Let’s also define a reusable function, plotPerformance, to plot the performance comparison between the different http request methods we’ll use.
1
2
3
4
5
6
7
8
def plotPerformance(performance_results):
df = DataFrame(performance_results)
g = sns.factorplot(x='N', y='seconds', hue='method',
data=df, size=7, ci=None)
g.set_axis_labels('N (# http requests)', 'Total Time to Complete (seconds)')
plt.title('Performance of different http request methods vs. number of http requests')
Next, we define a function timefunc we’ll use to measure the time (in seconds) each of our functions takes to complete.
1
2
3
4
5
6
7
8
9
10
11
12
13
def timefunc(f):
'''
Time profiling function adapted from "Simple Timers" example at
https://zapier.com/engineering/profiling-python-boss/
'''
def f_timer(*args, **kwargs):
start = time.time()
result = f(*args, **kwargs)
end = time.time()
elapsed_time = end - start
print f.__name__, 'took', elapsed_time, 'seconds'
return (result, elapsed_time)
return f_timer
Base Case: Making N HTTP Requests with requests
The first function we’ll write to make http requests is makeRequestsBase, our “base” or “simplest” case, where we make N number of calls to our url using requests.get(url).
1
2
3
4
5
6
7
@timefunc
def makeRequestsBase(url, N):
'''
Function to make `N` number of requests.get calls to `url`
'''
for i in range(N):
requests.get(url)
1
performance_results += simulateHttpRequests(makeRequestsBase, url, 'Base')
1
2
3
4
5
makeRequestsBase took 22.2858679295 seconds
makeRequestsBase took 56.5521509647 seconds
makeRequestsBase took 54.9886300564 seconds
makeRequestsBase took 91.8658950329 seconds
makeRequestsBase took 109.037662029 seconds
1
plotPerformance(performance_results)
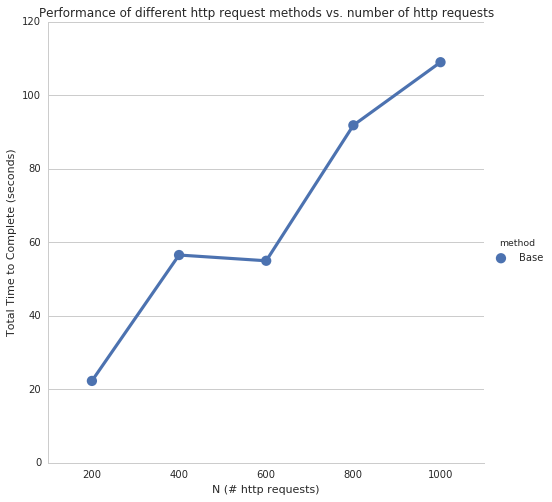
As you can see, the time to complete all http requests directly increases with an increase in N http requests. Translation: Need to make a lot of separate requests.get() calls? You’re going to have to wait a while. Let’s see if we can do better…
Using Sessions with requests.Session()
Next, since we’re making repeated requests to the same url, let’s see if we can use requests.Session() so we can reuse the underlying TCP connection and hopefully get a significant performance increase.
1
2
3
4
5
6
7
8
9
@timefunc
def makeRequestsWithSession(url, N):
'''
Use `requests.Session` to make `N` number of
`requests.Session().get` calls to `url`
'''
session = requests.Session()
for i in range(N):
session.get(url)
1
performance_results += simulateHttpRequests(makeRequestsWithSession, url, 'Sessions')
1
2
3
4
5
makeRequestsWithSession took 15.066172123 seconds
makeRequestsWithSession took 25.9786450863 seconds
makeRequestsWithSession took 48.7462890148 seconds
makeRequestsWithSession took 60.7137110233 seconds
makeRequestsWithSession took 74.8754990101 seconds
1
plotPerformance(performance_results)
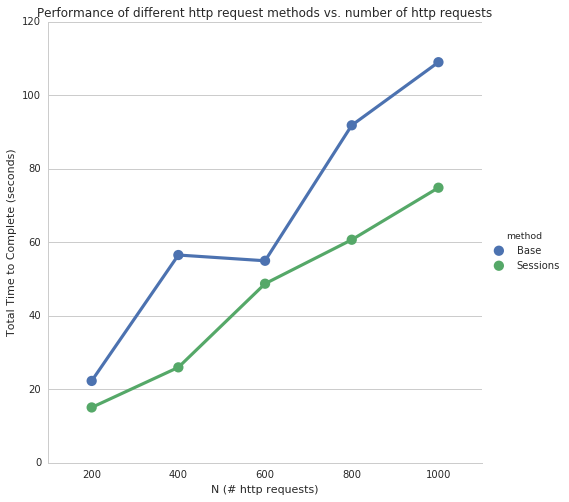
Based on the results, using requests.Sessions() on repeated http requests improves the performance significantly. For example, using Sessions takes ~60% as much time as using repeated requests.get() (~70 seconds vs. ~110 seconds).
Using Pooling with gevent.pool
It looks like using requests.Session() to make http requests is better than makeRequestsBase, but can we do even better?
In our next function, makeRequestsWithPooling, we make the same requests.get calls, except this time we wrap each of the N calls in a gevent.pool.
1
2
3
4
5
6
7
8
9
10
@timefunc
def makeRequestsWithPooling(url, N):
'''
Use `gevent.pool` library to make `N` number of requests.get
calls to `url` using a `pool` of `size` = `N`
'''
pool = Pool(25)
for i in range(N):
pool.spawn(requests.get, url)
pool.join()
1
performance_results += simulateHttpRequests(makeRequestsWithPooling, url, 'Pooling')
1
2
3
4
5
makeRequestsWithPooling took 2.18829607964 seconds
makeRequestsWithPooling took 3.18417310715 seconds
makeRequestsWithPooling took 6.19790005684 seconds
makeRequestsWithPooling took 6.60030603409 seconds
makeRequestsWithPooling took 7.90286302567 seconds
1
plotPerformance(performance_results)
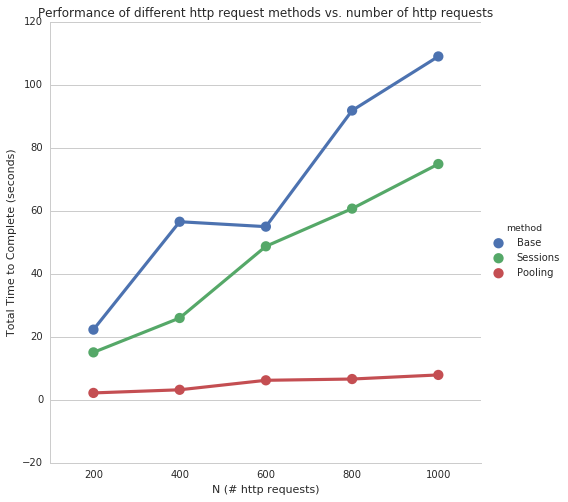
Now we’re talking! Using gevent.pool seems to significantly improve the speed with which we can make repeated http requests, without much additional cost in time as N increases.
Using Sessions and Pooling
Can we do even better if we combine the requests.Session() and gevent.pool methods?
1
2
3
4
5
6
7
8
9
10
11
@timefunc
def makeRequestsWithSessionAndPooling(url, N):
'''
Combine `gevent.pool` and `requests.Session` techniques to make
`N` number of `requests` calls to `url`
'''
session = requests.Session()
pool = Pool(25)
for i in range(N):
pool.spawn(session.get, url)
pool.join()
1
performance_results += simulateHttpRequests(makeRequestsWithSessionAndPooling, url, 'Sessions and Pooling')
1
2
3
4
5
makeRequestsWithSessionAndPooling took 1.01481890678 seconds
makeRequestsWithSessionAndPooling took 1.43802595139 seconds
makeRequestsWithSessionAndPooling took 2.82900905609 seconds
makeRequestsWithSessionAndPooling took 3.96559691429 seconds
makeRequestsWithSessionAndPooling took 4.88879513741 seconds
1
plotPerformance(performance_results)
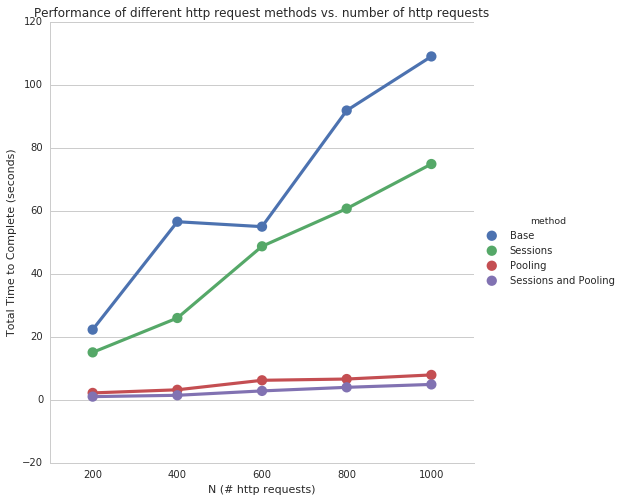
Based on the simulated data, combining requests.Session() and gevent.pool doesn’t improve much on simply gevent.pool.
Conclusion
I ended up using the gevent.pool method which allowed me to scrape all 9000+ movies from BoxOfficeMojo.com from 2000-2015 in ~2 minutes! A big improvement in the 15+ minutes it would have taken me to scrape the same amount of data with the “Base case” using repeated requests.get() calls.
Why didn’t I use the combined requests.Session() and gevent.pool methods? Simplicity / less moving parts, especially given the combined method didn’t offer much of a performance improvement.
Potential Next Steps
This was my first experience using the gvent package so I’d like to experiment with it in more detail and see what similar options are available. For example, I’d like to experiment to find the optimal size of the gevent.pool. In this post I chose a pool size of 25 based off some quick experimentation of using different values. I noticed above a value of 25, the performance increase was barely noticeable, but I’d like to explore in more detail why that might be.
Anyways, until next time and happy scraping!
Source
You can check out this Jupyter Notebook on my Github repository to see the full source for this post.