Project 3 - Can we predict if an Amazon review will be helpful or not?
For project 3, code-named “McNulty,” the goal was to gain exposure to classification methods, understanding of their use, and practice implementing them using scikit-learn. For my project, I chose to classify if an Amazon Kindle Review would be helpful or not-helpful.

Even if we can predict review helpfulness, so what?
Being able to predict review helpfulness can be beneficial for both sides of the e-commerce market.
The value for e-commerce sites (e.g., Amazon):
- More relevant review search results and layout
- Help identify spam reviews
The value for consumers/reviewers:
- Provide reviewers recommendations for how to write reviews to maximize helpfulness at time of writing
Review helpfulness in context
To help understand what I mean by “helpfulness,” let’s take a look at how Amazon users vote on whether a review is helpful or not, as well as how I calculated review helpfulness.
Anatomy of an Amazon review
As seen in the image below, Amazon allows users to click a button on each review to indicate whether it was helpful or not-helpful.
Defining review helpfulness
The dataset I used provided the number of helpful and not-helpful votes for each review. Therefore, I defined helpfulness as a binary variable as follows.
1
2
helpfulness_ratio = total_helpful_votes / (total_helpful_votes + total_not_helpful_votes)
helpfulness = 1 when helpfulness_ratio >= 0.5 (i.e., helpful), -1 otherwise (i.e., not-helpful)
Defining helpfulness as a binary variable enabled me to set this up as a binary classification problem.
The Data
For this project, I started with 3 million+ reviews of Amazon Kindle books from 1996 - 2015, preprocessed by UCSD CS professor Julian McAuley1 2 3. For the final dataset I used to run the models, I only used reviews with 10 or more helpful/not-helpful votes (65,000+ reviews) to help focus the analysis.
To prepare the data, I used a 75% / 25% train/test split. I also upsampled the not-helpful data in the train set to balance the helpful/not-helpful classes.
Model features
To classify reviews as helpful or not-helpful, I used the following features:
- Text (review length, readability4, semantic patterns using TFIDF5)
- Reviewer experience (previous helpful/not-helpful votes for prior reviews, average of previous overall ratings)
- Review overall rating (i.e., number of stars)
Note: I balanced the classes for the training dataset by upsampling the not-helpful data to help improve precision and recall for the not-helpful class because of the class imbalance.
Choosing the best classifier
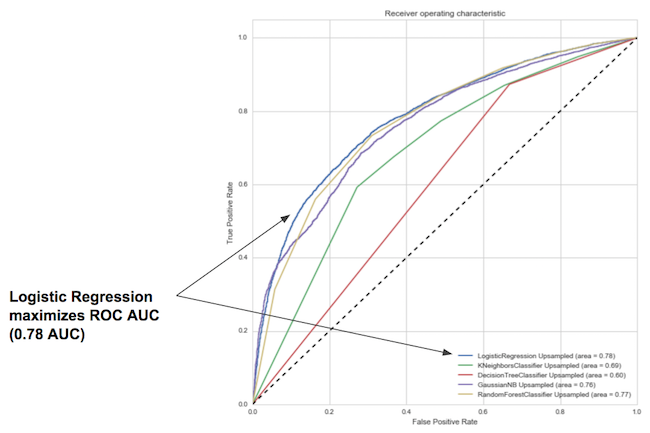
To determine the best classifier, I ran different classification algorithms (LogisticRegression, KNeighborsClassifier, DecisionTreeClassifier, RandomForestClassifier, and GaussianNB) using sklearn and compared the results using a ROC curve. The image below shows that the logistic regression classifier performs the best with respect to maximizing area under the ROC curve.
Final model test results
Let’s drill down on the logistic regression results since it performed the best relative to the other classifiers. The image below shows the confusion matrix for the logistic regression classifier results on the test data set.
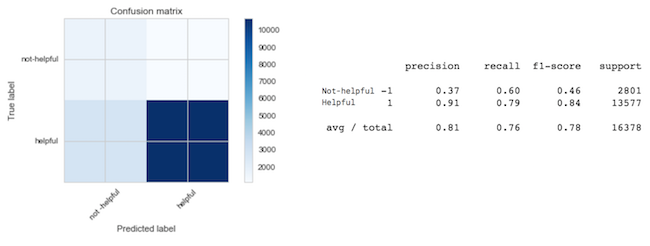
As you can see, precision and recall are high for the helpful class which is expected given the significantly higher number of helpful reviews in the test set (13577 helpful reviews vs. 2801 not-helpful reviews). Precision and recall are low for the not-helpful class, but are an improvement on using a baseline dummy classifier that predicts helpful each time which would result in 0% precision and 0% recall to the not-helpful class.
Are you smarter than a logistic regression classifier?
Want to compare your ability to predict if a review is helpful vs. the logistic regression model I developed? Try out this interactive Flask app now!
Warning: The app randomly samples 10 reviews from a seed of 1000 stored reviews. Some of the books and reviews are strange. Don’t say I didn’t warn you!
Here’s a screenshot of the app:

Conclusion
Based on the model I developed, it’s difficult to distinguish not-helpful reviews from the helpful reviews. However, the model improves our ability to detect not-helpful reviews when compared to a dummy classifier that predicts all reviews as helpful. Additionally, of all our model features, review star rating and the text features are the most important features to distinguish between helpful / not-helpful reviews.
Future work
Potential future work to improve and/or extend the work I did on classifying review helpfulness may include:
- Analyzing data on review comments
- Refining model text features
- Incorporating “authenticity” as a feature by analyzing reviews for spam
- Analyzing model performance against other Amazon department reviews and/or a subcategory of Kindle Store reviews
- Developing app that provides guidance to Amazon Kindle store reviewers on how to make their reviews more helpful at the time of writing a review
What I learned
The following are the major things I learned during project McNulty:
- Familiarity with classification methods using sklearn
- Classification metrics. Why accuracy alone is a bad measure for classification tasks, and what we can do about it
- NLP techniques such as TF-IDF and SVD
- Deploying a Flask app to AWS EC2 Container Services (ECS) using Docker. I packaged my Flask app as a Docker container and published it to the Docker hub here. I then deployed the Docker image as a Docker container on AWS ECS. Check out the app here.
- Using D3. I used D3 to display a graph of the game results in my Flask app.
- Persisting data in a data store / database when working with big data. To persist the 3 million+ reviews to disk to make them easier to work with, I stored the review data in a combination of Elasticsearch, Mongo, and Postgres data stores.
Footnotes
-
Image-based recommendations on styles and substitutes J. McAuley, C. Targett, J. Shi, A. van den Hengel SIGIR, 2015 pdf ↩
-
Inferring networks of substitutable and complementary products J. McAuley, R. Pandey, J. Leskovec Knowledge Discovery and Data Mining, 2015 pdf ↩
-
Readability - Automated Readability Index (ARI); see Calculating ARI ↩
-
Used sklearn TFIDFVectorizer and TruncatedSVD to generate TFIDF features. ↩