Key Apache Spark Trends from Spark Summit East 2017
I was lucky enough to attend Spark Summit East 2017 February 8-9. I had to brave the 12” of snow blizzard Nico brought to Boston, but overall learned a lot about the strategic direction of the Apache Spark open source project and ecosystem. In this post I’ll fill you in on the key Spark trends from the conference. This post will be helpful if you are part of an organization that is currently using Spark, looking to use Spark, or you are just personally interested in Spark.

Disclaimer: The opinions expressed in this article are my own and do not reflect the view of any other individuals or organizations.
Spark moves to Primetime: Key Spark Trends from Spark Summit East 2017
The overarching theme I took away from the conference was: Spark moves to Primetime. In other words, Spark is maturing from a tool used by “early adopter” analytics shops (small startups or corporations with mature analytics departments that use it mostly for development or offline analytics) to “early majority” analytics shops (large data-driven organizations that require tools be enterprise/production-ready). For those of you familiar with Geoffrey Moore’s book, Crossing the Chasm, this is the “Chasm” for Spark adoption.

The Spark in Primetime theme was clear in the conference’s significant focus on Enterprise/Production-ready Spark. There was much discussion about making Spark more real-time focused, secure, and easier to operate (e.g., easier for IT to deploy and manage; easier for data scientists to access). The whole second day of the conference was even themed Enterprise Day!
The Spark community made a lot of these enterprise/production-ready features available in the recently released Spark 2.0. The newly formed Berkeley RISELab, the successor to the Berkeley AMPLab, is looking to take them to the next level.
Easier to Operationalize Spark
The learning-curve and sustainability of a tool are frequently big hurdles to adoption. There was a strong focus on how to make Spark easier to operate (e.g., deploy, access, and manage) in an effort to decrease the learning-curve and make it a more sustainable solution.
Matei Zaharia, creator of the Spark project, discussed in his keynote how Spark helps “democratize access to data.” In other words, data engineers / scientists have the luxury of choosing from several programming languages when they write Spark code, including the more recent addition of R. Additionally, the high-level Spark APIs (Spark SQL, DataFrames, ML Pipelines, PySpark, SparkR) make Spark development easier.

In addition to easier access to data, many vendors in the Spark ecosystem pitched ways to simplify Spark deployment and management. The main sponsor, Databricks, heavily pushed the capabilities of their Spark cloud platform. The conference goodie bag had several flyers marketing “Data Science Sandbox” and “Data Science as a Service” solutions. BlueData presented on running Spark in Docker containers. Openshift discussed their platform, built on Docker and Kubernetes, that enables a “fully elastic Spark application with little more than the click of a button.” All this focus on making it easier to operationalize Spark will help drive overall Spark growth.

“Continuous Applications”
While there are countless tools available to address streaming, batch, or data serving analytics workloads, it is difficult to create apps that integrate all three workloads. With Spark 2.0 (specifically Spark Structured Streaming), Spark aims to provide a single API for what Databricks is coining “continuous apps” - apps that merge streaming and batch workloads.
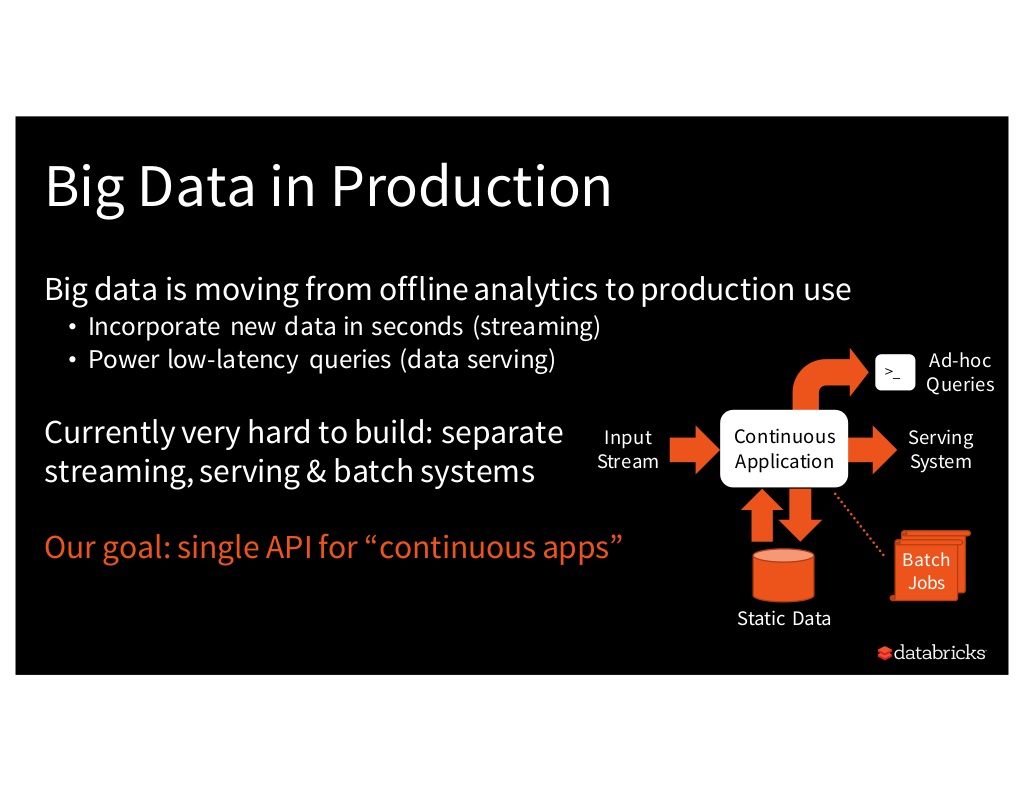
Similarly, the Principal Product Manager for MemSQL, Steven Camina, discussed the massive opportunity of converting existing batch processes to real-time.

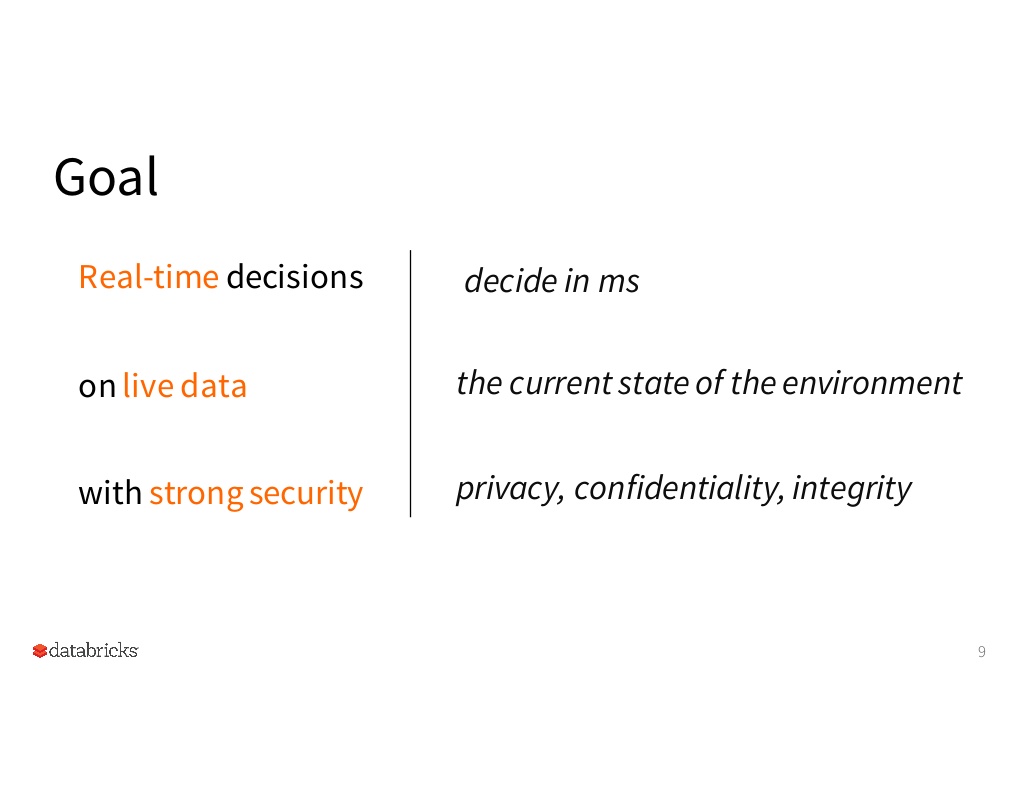
Going forward, the Berkeley RISELab will have a heavy focus on enabling “continuous apps” given the group’s “real-time” focus:
Faster Big Data Analytics
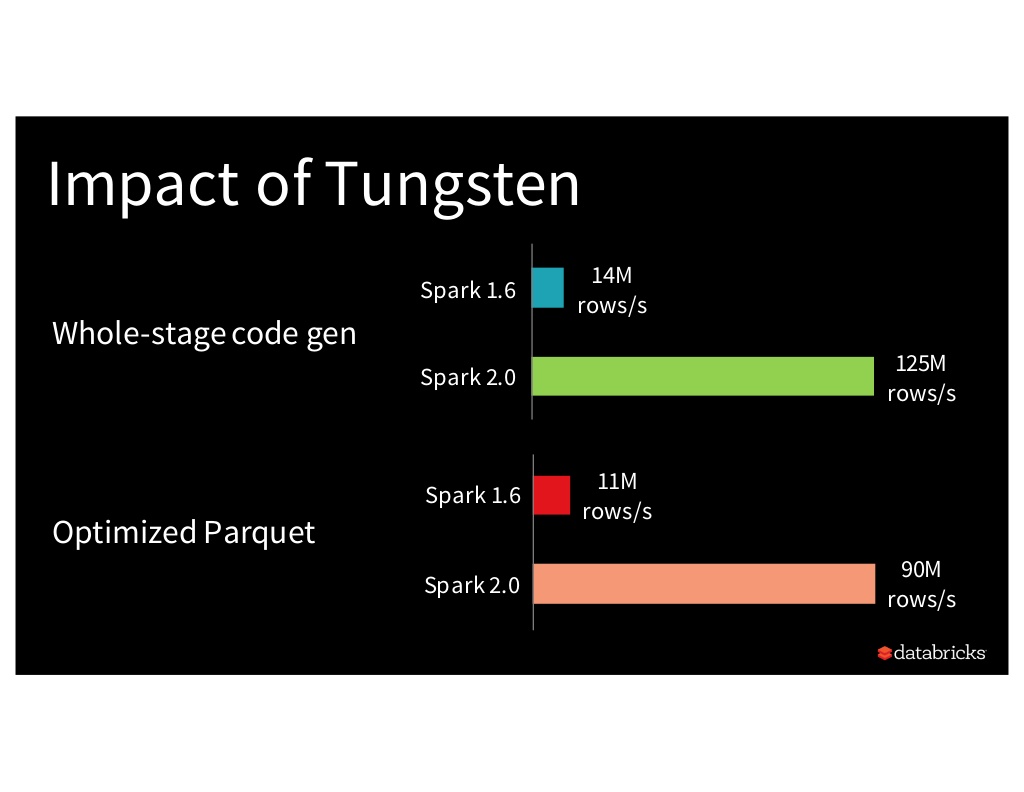
Right now, a major performance issue with big data analytics is the compute bottleneck. While storage and network performance improved ~10x since 2010, CPU performance has remained relatively stagnant.
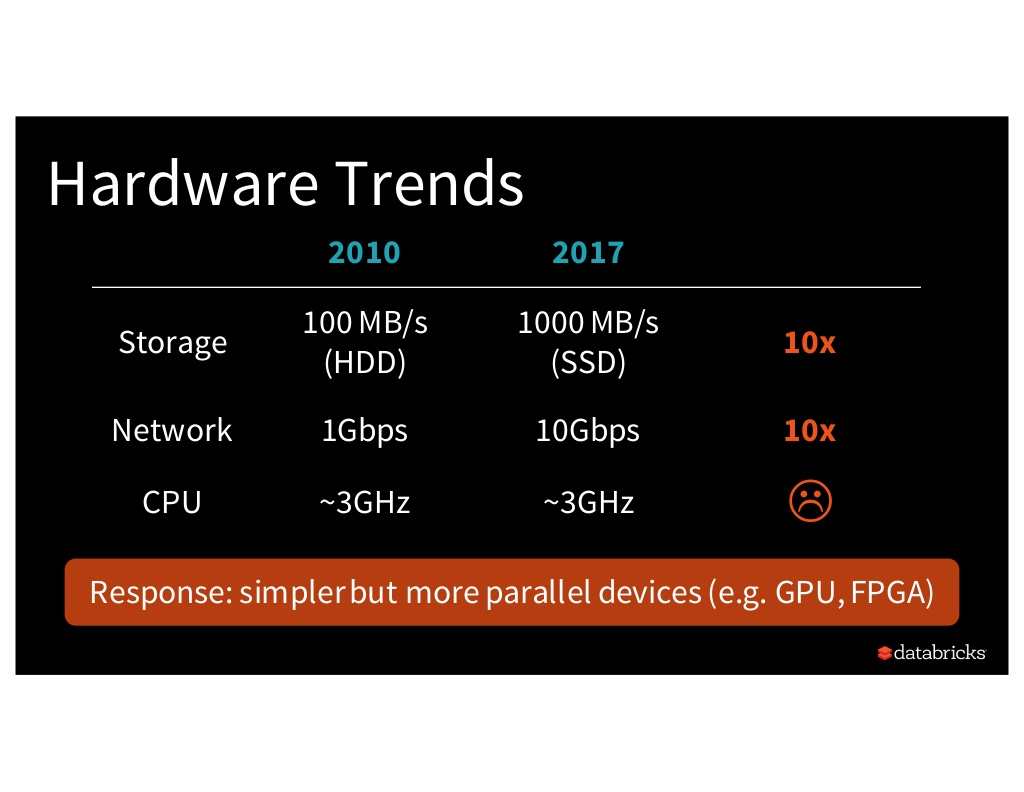
To address this issue, the Spark community created Project Tungsten with the goal of optimizing Spark CPU and memory usage.
Security
A big hurdle to Enterprise adoption and Production use is security. Spark security is about to get a big upgrade with the introduction of the Berkeley RISELab.
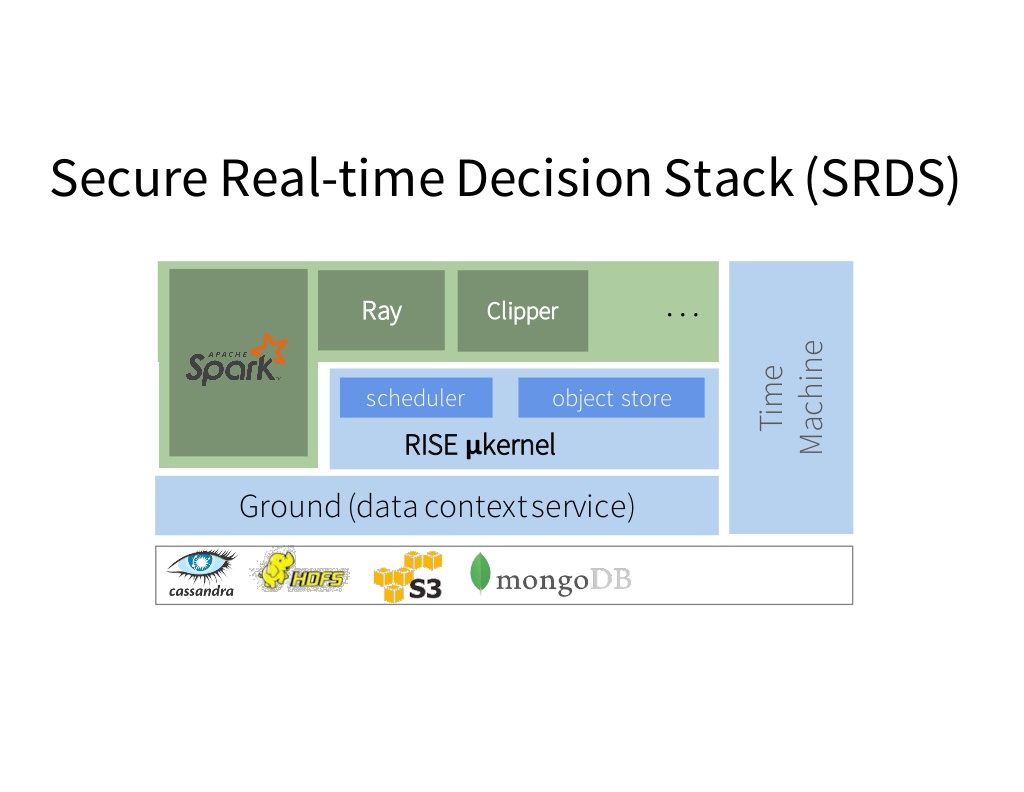
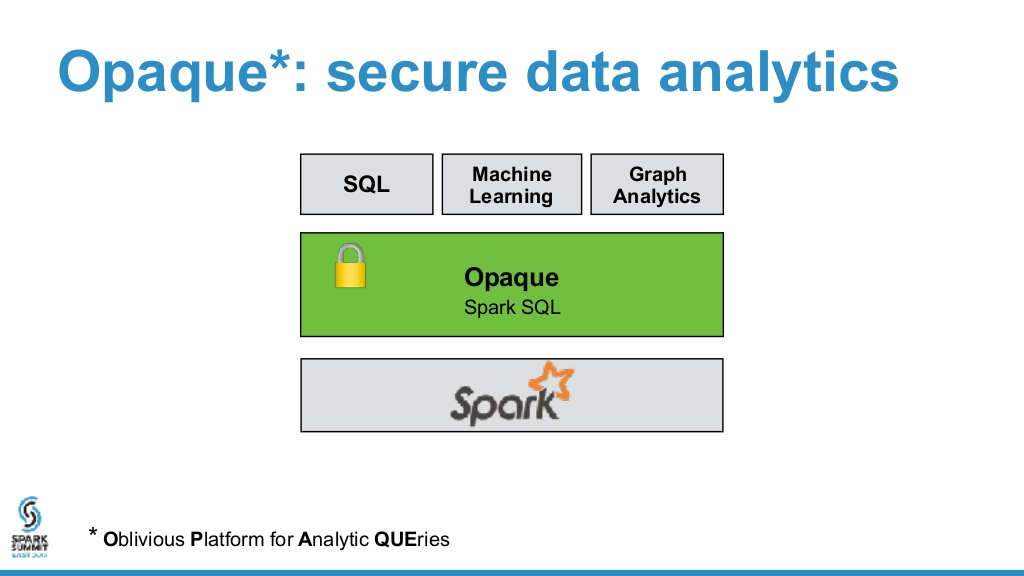
As I mentioned earlier, the goal of the RISELab is to enable “Real-time decisions on live data with strong security.” The RISELab has two projects to address the “strong security” component:
- Secure Real-time Decisions Stack (SRDS): open source platform to develop RISE apps, secure from the ground up
- Opaque: secure distributed data analytics framework
What’s next?
As Spark makes the move to Primetime, crossing the chasm to the “early majority” of true enterprise adoption, will you take advantage of all that Spark can do for you?
To learn more about how Spark can help you, check out all the presentation videos and slides from Spark Summit East 2017.